15 KiB
GCNet Global Context
注意力机制:捕获全文关系
Abstract
Non-local Net 【CV中的Attention机制】Non-Local Network的理解与实现 - 知乎 (zhihu.com)
Non-Local Network是一种神经网络结构,它的特点是能够捕捉输入信号中不同位置之间的关系,而不仅仅是局部邻域的关系。例如,在视频分类任务中,Non-Local Network可以学习到视频中不同帧之间的动作和场景的联系,从而提高分类的准确性。
Non-Local Network的基本公式如下:
y_i=\frac {1} {C (x)}\sum_ {\forall j}f (x_i,x_j)g (x_j)其中:
• $x$是输入信号,可以是图像、序列、视频等,或者它们的特征表示。
• $y$是输出信号,和$x$的形状相同。
• $i$是输出位置的索引,可以是空间、时间或者时空的坐标,比如第8帧的(32,46)位置。
• $j$是所有可能的位置的索引,用于遍历整个输入信号。
• $f(x_i,x_j)$是一个二元函数,用于计算位置$i$和位置$j$之间的相似度或权重。相似度越高,权重越大,表示两个位置之间的联系越紧密。
• $g(x_j)$是一个一元函数,用于对位置$j$的特征做一个变换。通常使用一个1x1的卷积操作来实现。
• $C(x)$是一个归一化函数,用于将所有位置$j$对位置$i$的贡献加起来,并除以一个常数。这样可以保证输出信号的数值范围不会过大或过小。
Non-Local Network的工作原理是这样的:
• 对于每个输出位置$i$,我们要计算它和所有其他位置$j$之间的相似度或权重$f(x_i,x_j)$。这样就得到了一个权重矩阵,表示输入信号中每两个位置之间的关系。
• 然后我们对每个位置$j$的特征做一个变换$g(x_j)$,得到一个变换后的特征矩阵。
• 接着我们用权重矩阵和变换后的特征矩阵做一个矩阵乘法,得到一个加权后的特征矩阵。这个矩阵表示每个位置$i$受到所有其他位置$j$的影响后的特征。
• 最后我们用归一化函数$C(x)$对加权后的特征矩阵做一个归一化处理,得到最终的输出信号
y
NLNet提出了一种开拓性的方法,通过聚合查询特定的全局上下文到每个查询位置捕获远程依赖关系。然而,通过严格的实证分析,==我们发现对于图像中的不同查询位置,非局部网络所建模的全局上下文几乎是相同的==。在本文中,我们利用这一发现,创建一个简化的网络的基础上查询独立的配方,保持NLNet的准确性,但显着较少的计算。我们进一步观察到,这种简化的设计共享与压缩激励网络(SENet)类似的结构。因此,我们统一到一个三步的通用框架的全局上下文建模。在通用框架内,我们设计了一个更好的实例化,称为全局上下文(GC)块,它是轻量级的,可以有效地建模全局上下文。轻量级的属性允许我们将其应用于骨干网络中的多个层以构建全局上下文网络(GCNet),其在各种识别任务的主要基准测试中通常优于简化的NLNet和SENet
Introduction
- 捕获远程依赖关系,提取视觉场景的全局理解,被证明有利于广泛的识别任务: 堆叠重复的卷积层是低效的,因为很难在不同距离的位置传递信息
- ==non-local network==[31],通过自注意机制,使用一层来建模长程依赖关系。对于每个查询位置,非局部网络首先计算查询位置与所有位置之间的成对关系以形成注意力图,然后通过与由注意力图定义的权重的加权和来聚合所有位置的特征。最后将聚合的要素添加到每个查询位置的要素中以形成输出
- 通过可视化注意力图谱,发现不同查询位置的注意力图fig1几乎相同,这表明只学习了与查询无关的依赖关系
- 通过表1中的统计分析进一步验证了该观察结果,即不同查询位置的注意力图之间的差距非常小。
- 基于上述的发现,我们通过对所有的query 位置使用query-无关的attention map,来简化non-local block.然后,我们使用该注意力图将相同的聚合特征添加到所有查询位置的特征中,以形成输出。降低了模型和计算复杂度。和SENet相似,它们都是通过从各个位置聚合相同的特征来强化原有特征,但在聚合策略、转换和强化功能的选择上有所区别。
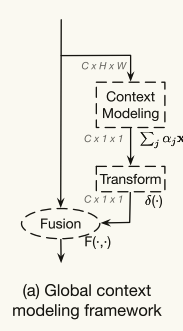
- 从NL block和SE block ,提出三步的通用框架:
- (a)上下文建模模块,其将所有位置的特征聚集在一起以形成全局上下文特征;(b)特征变换模块,其捕获通道方向的相互依赖性;以及(c)融合模块,其将全局上下文特征合并到所有位置的特征中。
- ==GC block在上下文建模(使用全局注意力池)和融合(使用加法)步骤上与简化的NL块共享相同的实现,而与SE块共享相同的变换步骤(使用两层瓶颈)==。
- 与SE块一样,所提出的GC块也是轻量级的,这允许其应用于ResNet架构中的所有残差块,与NL block形成对比,NL block由于其繁重的计算而通常在一层或几层之后应用。GC块增强网络被命名为全局上下文网络(GCNet)
- 在COCO对象检测/分割方面,GCNet在APbox上的表现分别优于NLNet和SENet 1.9%和1.7%,在APmask上分别优于NLNet和SENet 1.5%和1.5%,而FLOP仅相对增加0.07%。此外,GCNet在三个一般视觉识别任务上产生了显着的性能提升:COCO上的目标检测/分割(在APbbox上为2.7%↑,在以FPN和ResNet-50为骨干的Mask R-CNN上为2.4%↑ [9]),ImageNet上的图像分类(在ResNet-50上的前1个准确率为0.8%↑ [10]),在Kinetics上的动作识别(在ResNet-50慢基线上的前1个准确率为1.1%↑ [6]),计算成本增加不到0.26%。
Related work
-
Deep architecture
-
Long-range dependency modeling
NLNet [31]采用自我注意机制来建模像素级成对关系。CCNet [16]通过堆叠两个交叉块来加速NLNet,并应用于语义分割。然而,NLNet实际上为每个查询位置学习独立于查询的注意力图,这是对像素级成对关系建模的计算成本的浪费。为了对全局上下文特征进行建模,SENet [14],GENet [13]和PSANet [41]对不同的通道进行重新缩放,以重新校准具有全局上下文的通道依赖性。CBAM [32]通过重新缩放来重新校准不同空间位置和通道的重要性。==然而,所有这些方法采用重缩放的特征融合,这是不够有效的全局上下文建模。==
-
==所提出的GCNet可以通过加法融合有效地对全局上下文建模为NLNet [31](其是重量级的并且难以集成到多个层),具有轻量级属性为SENet [14](其采用缩放并且对于全局上下文建模不够有效)==。因此,通过更有效的全局上下文建模,GCNet可以在各种识别任务的主要基准上实现比NLNet和SENet更好的性能。
Analysis on Non-local Networks
Non-local Block
通过聚合来自其他位置的信息来加强查询位置的特征。
具体的计算细节在论文3.1节
Wk和Wq计算相似性f,然后Softmax相当于C(x),与用Wv进行特征变换的结果进行矩阵相乘
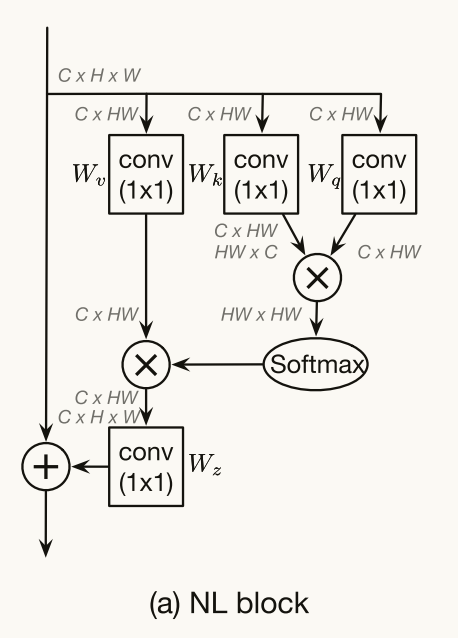
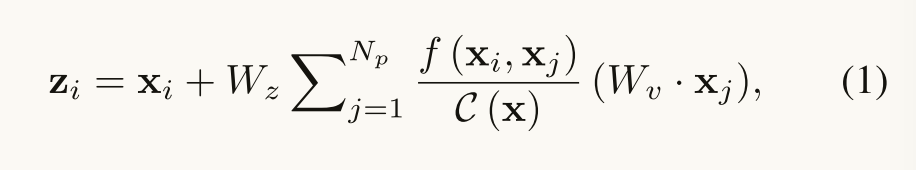
Non-local Block可以被认为是全局上下文建模块,其将查询特定的全局上下文特征(经由查询特定的注意力图从所有位置加权平均)聚集到每个查询位置。由于注意力图是为每个查询位置计算的,因此非局部块的时间和空间复杂度都是位置数量Np的二次函数。
Analysis
-
Visualization
根据用于对象检测的非局部网络的标准设置[31],我们使用FPN和Res 50对Mask R-CNN进行实验,并且仅在res 4的最后一个残差块之前添加一个非局部块.对于不同的查询位置,它们的注意力地图几乎是相同的
-
Statistical Analysis
首先,输入列中的cosine distance表明,可以在不同位置区分非局部块的输入特征。但是输出中的cosine distance很小,这表明非局部块建模的全局上下文特征对于不同的查询位置几乎是相同的。注意图上的两个距离度量(‘ATT’)对于所有实例化都非常小,这再次验证了从可视化观察到的结果。
Method
Simplifying the Non-local Block
基于观察,不同的查询位置的注意力地图几乎是相同的,我们简化了Non-local Blockt通过计算一个全局(查询无关)的注意力图和并且在所有的query position共享这个全局注意力图
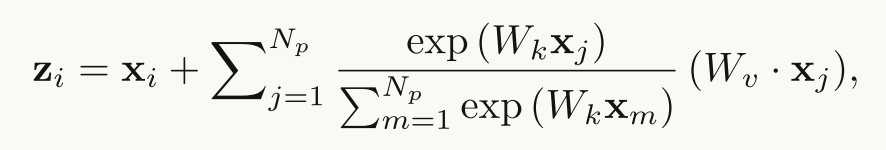
进一步减小计算move Wv 放到外面
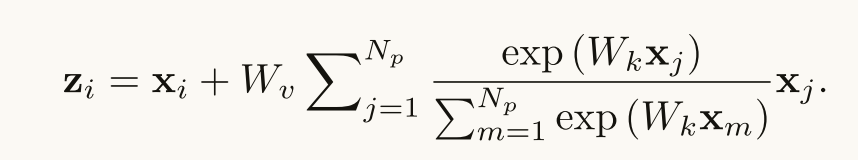
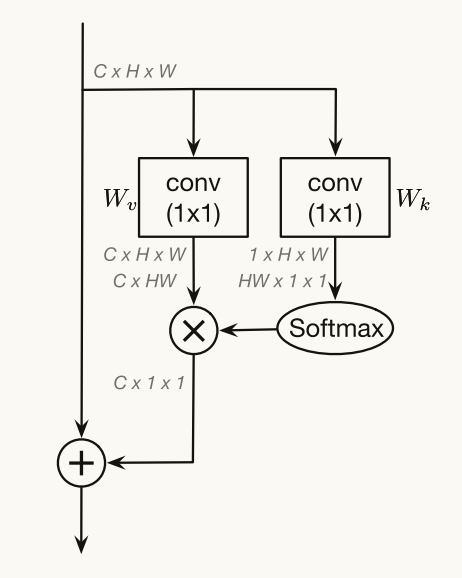
与传统的非局部块不同,公式3中的第二项与查询位置i无关,这意味着该项在所有查询位置i之间共享。最后那个W z也去掉了 因为对模型没什么影响
我们直接将全局上下文建模为所有位置处的特征的加权平均值,并将全局上下文特征聚合(添加)到每个查询位置处的特征。在实验中,我们直接用简化的非本地(SNL)块替换非本地(NL)块,并评估三个任务的准确性和计算成本,COCO上的对象检测,ImageNet分类和动作识别,如表2(a),4(a)和5所示。正如我们所预期的,SNL块实现了与NL块相当的性能,但FLOP显著降低。
Global Context Modeling Framework
如图4(B)所示,简化的非局部块可以抽象为三个过程:(a)全局注意力池化,采用1 × 1卷积Wk和softmax函数获得注意力权重,然后进行注意力池化以获得全局上下文特征;(b)通过1 × 1卷积Wv进行特征变换;(c)特征聚合,其采用加法将全局上下文特征聚合到每个位置的特征。
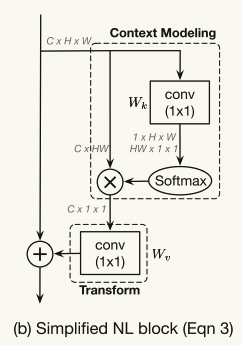
我们把这个抽象看作是一个全局上下文建模框架
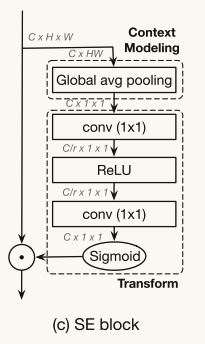
这和SE block很相似。(a) 全局平均池化为了全文建模 Squeeze operation(b)用依次是一个1x1卷积、一个ReLU、一个1x1卷积和一个sigmoid函数),以计算每个通道的重要性(c)进行通道融合,将通道权重加到原始特征图上
Global Context Block
在这里,我们提出了一个新的实例化的全局上下文建模框架,命名为全局上下文(GC)block,它具有简化的非本地(SNL)块与有效的建模长距离依赖,和挤压激励(SE)块与轻量级计算的好处。
在简化的非局部块中,如图4(b)所示,变换模块具有最大数量的参数,包括来自一个具有C·C参数的1x 1卷积。当我们将这个SNL块添加到更高层时,例如res 5,这个1x 1卷积的参数数量C·C=2048·2048,主导了这个块的参数数量。为了获得SE块的轻量级属性,这个1x 1卷积被bottleneck transform模块所取代,这将参数的数量从C·C显著减少到2·C·C/r,==其中r是瓶颈比率,C/r表示瓶颈的隐藏表示维度==。在默认缩减比率设置为r=16的情况下,用于变换模块的参数的数量可以减少到原始SNL块的1/8。
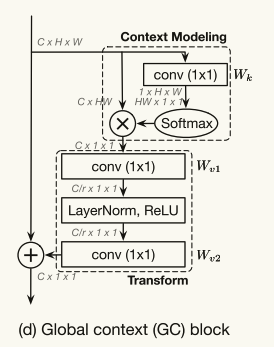
由于两层瓶颈变换增加了优化的难度,我们在瓶颈变换内部(在ReLU之前)添加了LayerNorm以简化优化,并作为一个正则化器,有利于泛化。如表2(d)所示,层归一化可以显著增强COCO上的对象检测和实例分割。
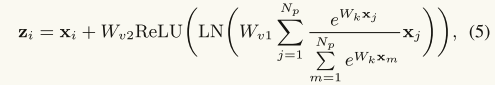
由于GC块是轻量级的,它可以应用于多个层,以更好地捕获长距离依赖关系,而计算成本只会略有增加。
- Relationship to non-local block.
- GC block的全局注意力池化模块和NL block建模相同,但是计算量显著降低,采用bottleneck减少了上下文特征的冗余
- Relationship to squeeze-excitation block.
- SE块和我们的GC块之间的主要区别是融合模块,这反映了两个块的不同目标。SE块采用重新缩放来重新校准通道的重要性,但不能充分模拟长距离依赖性。我们的GC块遵循NL块,利用加法将全局上下文聚合到所有位置,以捕获长期依赖性。
- 第二个区别是瓶颈变换中的层规范化。由于我们的GC块采用加法进行融合,层规范化可以简化两层架构的瓶颈转换优化,从而获得更好的性能。
- 第三,SE块中的全局平均池化是GC块中的全局注意力池化的特殊情况。
Experiments
目标检测、实例分割--COCO2017 分类--Imagenet
我们的实验是用PyTorch实现的[23]。除非另有说明,我们的比率r=16的GC块应用于ResNet/ResNeXt的阶段c3,c4,c5。
我们使用Mask R-CNN的标准配置[9],其中FPN和ResNet/ResNeXt作为骨干架构。
Ablation Study
- Block
- Position
- 在残差模块后 还是1x1的卷积核后 效果一样
- Stages
- c3+c4+c5
- Bottleneck Design
- LayerNormalization有效果
- Bottleneck ratio
- ratio越大 参数量越小 但是指标会降一点点
- Pooling and fusion
- 我们的GCNet(att+add)显著优于SENet,因为它有效地建模了长距离依赖关系,并使用注意力池进行上下文建模,并添加了特征聚合
Experiments on Stronger Backbones
我们在更强的主干上评估我们的GCNet,用ResNet-101和ResNeXt-101替换ResNet-50 [34],将可变形卷积添加到多层(c3+c4+c5)[4,42]并采用级联策略[1]。
值得注意的是,即使采用更强大的主干,GCNet与基线相比的增益仍然很大,这表明我们的全局上下文建模GC块与当前模型的能力是互补的。对于最强的主干,在ResNeXt 101中使用可变形卷积和级联RCNN,我们的GC块仍然可以在APbbox上提高0.8%↑,
Conclusion
远程依赖建模的开创性工作,非本地网络,旨在建模查询特定的全局上下文,但只建模查询独立的上下文。在此基础上,我们简化了非局部网络,并将这个简化的版本抽象为一个全局上下文建模框架。然后,我们提出了一个新的实例化这个框架,GC块,这是轻量级的,可以有效地建模长距离依赖。我们的GCNet是通过将GC块应用于多个层来构建的,在各种识别任务的主要基准测试中,它通常优于简化的NLNet和SENet。