diff --git a/README.md b/README.md
index f2473b62..9f0c4893 100644
--- a/README.md
+++ b/README.md
@@ -22,7 +22,7 @@ If you like this project, please give it a Star. If you've come up with more use
>
> 2.本项目中每个文件的功能都在自译解[`self_analysis.md`](https://github.com/binary-husky/chatgpt_academic/wiki/chatgpt-academic%E9%A1%B9%E7%9B%AE%E8%87%AA%E8%AF%91%E8%A7%A3%E6%8A%A5%E5%91%8A)详细说明。随着版本的迭代,您也可以随时自行点击相关函数插件,调用GPT重新生成项目的自我解析报告。常见问题汇总在[`wiki`](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98)当中。
>
-
+> 3.已支持OpenAI和API2D的api-key共存,可在配置文件中填写如`API_KEY="openai-key1,openai-key2,api2d-key3"`。需要临时更换`API_KEY`时,在输入区输入临时的`API_KEY`然后回车键提交后即可生效。
@@ -40,6 +40,7 @@ If you like this project, please give it a Star. If you've come up with more use
Latex全文翻译、润色 | [函数插件] 一键翻译或润色latex论文
批量注释生成 | [函数插件] 一键批量生成函数注释
chat分析报告生成 | [函数插件] 运行后自动生成总结汇报
+Markdown中英互译 | [函数插件] 看到上面5种语言的[README](https://github.com/binary-husky/chatgpt_academic/blob/master/docs/README_EN.md)了吗?
[arxiv小助手](https://www.bilibili.com/video/BV1LM4y1279X) | [函数插件] 输入arxiv文章url即可一键翻译摘要+下载PDF
[PDF论文全文翻译功能](https://www.bilibili.com/video/BV1KT411x7Wn) | [函数插件] PDF论文提取题目&摘要+翻译全文(多线程)
[谷歌学术统合小助手](https://www.bilibili.com/video/BV19L411U7ia) | [函数插件] 给定任意谷歌学术搜索页面URL,让gpt帮你选择有趣的文章
@@ -53,7 +54,7 @@ huggingface免科学上网[在线体验](https://huggingface.co/spaces/qingxu98/
-- 新界面(修改config.py中的LAYOUT选项即可实现“左右布局”和“上下布局”的切换)
+- 新界面(修改`config.py`中的LAYOUT选项即可实现“左右布局”和“上下布局”的切换)
@@ -101,8 +102,8 @@ cd chatgpt_academic
在`config.py`中,配置 海外Proxy 和 OpenAI API KEY,说明如下
```
-1. 如果你在国内,需要设置海外代理才能够顺利使用 OpenAI API,设置方法请仔细阅读config.py(1.修改其中的USE_PROXY为True; 2.按照说明修改其中的proxies)。
-2. 配置 OpenAI API KEY。你需要在 OpenAI 官网上注册并获取 API KEY。一旦你拿到了 API KEY,在 config.py 文件里配置好即可。
+1. 如果你在国内,需要设置海外代理才能够顺利使用OpenAI API,设置方法请仔细阅读config.py(1.修改其中的USE_PROXY为True; 2.按照说明修改其中的proxies)。
+2. 配置 OpenAI API KEY。支持任意数量的OpenAI的密钥和API2D的密钥共存/负载均衡,多个KEY用英文逗号分隔即可,例如输入 API_KEY="OpenAI密钥1,API2D密钥2,OpenAI密钥3,OpenAI密钥4"
3. 与代理网络有关的issue(网络超时、代理不起作用)汇总到 https://github.com/binary-husky/chatgpt_academic/issues/1
```
(P.S. 程序运行时会优先检查是否存在名为`config_private.py`的私密配置文件,并用其中的配置覆盖`config.py`的同名配置。因此,如果您能理解我们的配置读取逻辑,我们强烈建议您在`config.py`旁边创建一个名为`config_private.py`的新配置文件,并把`config.py`中的配置转移(复制)到`config_private.py`中。`config_private.py`不受git管控,可以让您的隐私信息更加安全。)
@@ -110,19 +111,17 @@ cd chatgpt_academic
3. 安装依赖
```sh
-# (选择一)推荐
-python -m pip install -r requirements.txt
+# (选择I: 如熟悉python)推荐
+python -m pip install -r requirements.txt
+# 备注:使用官方pip源或者阿里pip源,其他pip源(如一些大学的pip)有可能出问题,临时换源方法:python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
-# (选择二)如果您使用anaconda,步骤也是类似的:
-# (选择二.1)conda create -n gptac_venv python=3.11
-# (选择二.2)conda activate gptac_venv
-# (选择二.3)python -m pip install -r requirements.txt
-
-# 备注:使用官方pip源或者阿里pip源,其他pip源(如一些大学的pip)有可能出问题,临时换源方法:
-# python -m pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
+# (选择II: 如不熟悉python)使用anaconda,步骤也是类似的:
+# (II-1)conda create -n gptac_venv python=3.11
+# (II-2)conda activate gptac_venv
+# (II-3)python -m pip install -r requirements.txt
```
-如果需要支持清华ChatGLM,需要额外安装更多依赖(不熟悉python者、电脑配置不佳者,建议不要尝试):
+如果需要支持清华ChatGLM后端,需要额外安装更多依赖(前提条件:熟悉python + 电脑配置够强):
```sh
python -m pip install -r request_llm/requirements_chatglm.txt
```
@@ -135,54 +134,48 @@ python main.py
5. 测试函数插件
```
- 测试Python项目分析
- input区域 输入 `./crazy_functions/test_project/python/dqn` , 然后点击 "解析整个Python项目"
-- 测试自我代码解读
+ (选择1)input区域 输入 `./crazy_functions/test_project/python/dqn` , 然后点击 "解析整个Python项目"
+ (选择2)展开文件上传区,将python文件/包含python文件的压缩包拖拽进去,在出现反馈提示后, 然后点击 "解析整个Python项目"
+- 测试自我代码解读(本项目自译解)
点击 "[多线程Demo] 解析此项目本身(源码自译解)"
-- 测试实验功能模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
+- 测试函数插件模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
点击 "[函数插件模板Demo] 历史上的今天"
- 函数插件区下拉菜单中有更多功能可供选择
```
-## 安装-方法2:使用docker (Linux)
+## 安装-方法2:使用Docker
1. 仅ChatGPT(推荐大多数人选择)
+
``` sh
# 下载项目
git clone https://github.com/binary-husky/chatgpt_academic.git
cd chatgpt_academic
-# 配置 海外Proxy 和 OpenAI API KEY
+# 配置 “海外Proxy”, “API_KEY” 以及 “WEB_PORT” (例如50923) 等
用任意文本编辑器编辑 config.py
# 安装
docker build -t gpt-academic .
-# 运行
+#(最后一步-选择1)在Linux环境下,用`--net=host`更方便快捷
docker run --rm -it --net=host gpt-academic
-
-# 测试函数插件
-## 测试函数插件模板函数(要求gpt回答历史上的今天发生了什么),您可以根据此函数为模板,实现更复杂的功能
-点击 "[函数插件模板Demo] 历史上的今天"
-## 测试给Latex项目写摘要
-input区域 输入 ./crazy_functions/test_project/latex/attention , 然后点击 "读Tex论文写摘要"
-## 测试Python项目分析
-input区域 输入 ./crazy_functions/test_project/python/dqn , 然后点击 "解析整个Python项目"
-
-函数插件区下拉菜单中有更多功能可供选择
+#(最后一步-选择2)在macOS/windows环境下,只能用-p选项将容器上的端口(例如50923)暴露给主机上的端口
+docker run --rm -it -p 50923:50923 gpt-academic
```
-2. ChatGPT+ChatGLM(需要对docker非常熟悉 + 电脑配置足够强)
+2. ChatGPT+ChatGLM(需要对Docker熟悉 + 读懂Dockerfile + 电脑配置够强)
``` sh
-# 修改dockerfile
+# 修改Dockerfile
cd docs && nano Dockerfile+ChatGLM
-# How to build | 如何构建 (Dockerfile+ChatGLM在docs路径下,请先cd docs)
+# 构建 (Dockerfile+ChatGLM在docs路径下,请先cd docs)
docker build -t gpt-academic --network=host -f Dockerfile+ChatGLM .
-# How to run | 如何运行 (1) 直接运行:
+# 运行 (1) 直接运行:
docker run --rm -it --net=host --gpus=all gpt-academic
-# How to run | 如何运行 (2) 我想运行之前进容器做一些调整:
+# 运行 (2) 我想运行之前进容器做一些调整:
docker run --rm -it --net=host --gpus=all gpt-academic bash
```
-## 安装-方法3:其他部署方式
+## 安装-方法3:其他部署方式(需要云服务器知识与经验)
1. 远程云服务器部署
请访问[部署wiki-1](https://github.com/binary-husky/chatgpt_academic/wiki/%E4%BA%91%E6%9C%8D%E5%8A%A1%E5%99%A8%E8%BF%9C%E7%A8%8B%E9%83%A8%E7%BD%B2%E6%8C%87%E5%8D%97)
@@ -201,7 +194,9 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash
---
-## 自定义新的便捷按钮(学术快捷键自定义)
+## 自定义新的便捷按钮 / 自定义函数插件
+
+1. 自定义新的便捷按钮(学术快捷键)
任意文本编辑器打开`core_functional.py`,添加条目如下,然后重启程序即可。(如果按钮已经添加成功并可见,那么前缀、后缀都支持热修改,无需重启程序即可生效。)
例如
```
@@ -217,19 +212,25 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash
 +2. 自定义函数插件
+
+编写强大的函数插件来执行任何你想得到的和想不到的任务。
+本项目的插件编写、调试难度很低,只要您具备一定的python基础知识,就可以仿照我们提供的模板实现自己的插件功能。
+详情请参考[函数插件指南](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)。
+
+
---
## 部分功能展示
-### 图片显示:
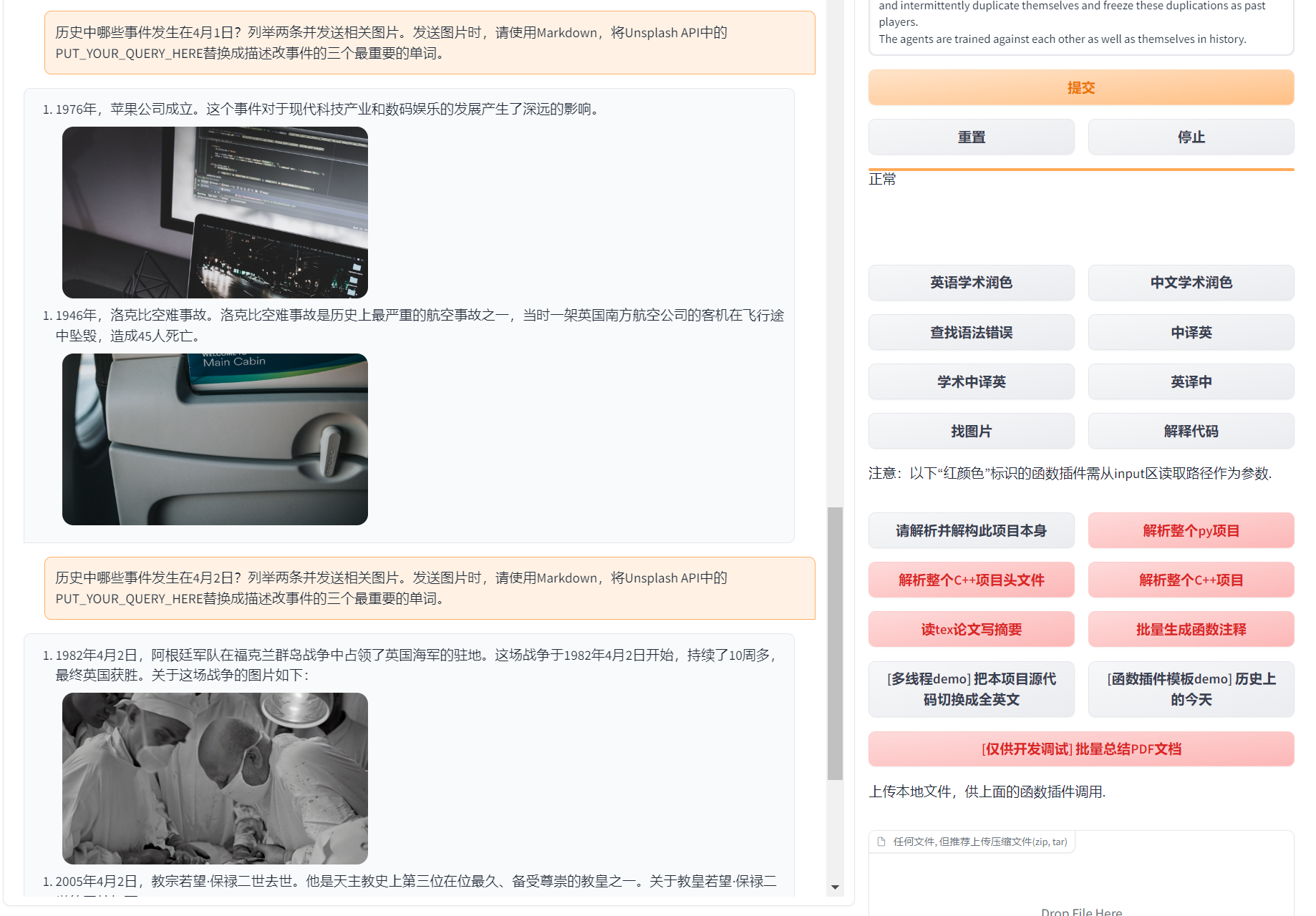
+1. 图片显示:
-
-### 如果一个程序能够读懂并剖析自己:
+2. 本项目的代码自译解(如果一个程序能够读懂并剖析自己):
+2. 自定义函数插件
+
+编写强大的函数插件来执行任何你想得到的和想不到的任务。
+本项目的插件编写、调试难度很低,只要您具备一定的python基础知识,就可以仿照我们提供的模板实现自己的插件功能。
+详情请参考[函数插件指南](https://github.com/binary-husky/chatgpt_academic/wiki/%E5%87%BD%E6%95%B0%E6%8F%92%E4%BB%B6%E6%8C%87%E5%8D%97)。
+
+
---
## 部分功能展示
-### 图片显示:
+1. 图片显示:
-
-### 如果一个程序能够读懂并剖析自己:
+2. 本项目的代码自译解(如果一个程序能够读懂并剖析自己):

@@ -239,7 +240,7 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash

-### 其他任意Python/Cpp项目剖析:
+3. 其他任意Python/Cpp/Java/Go/Rect/...项目剖析:
@@ -248,31 +249,39 @@ docker run --rm -it --net=host --gpus=all gpt-academic bash
 -### Latex论文一键阅读理解与摘要生成
+4. Latex论文一键阅读理解与摘要生成
-### 自动报告生成
+5. 自动报告生成
-### 模块化功能设计
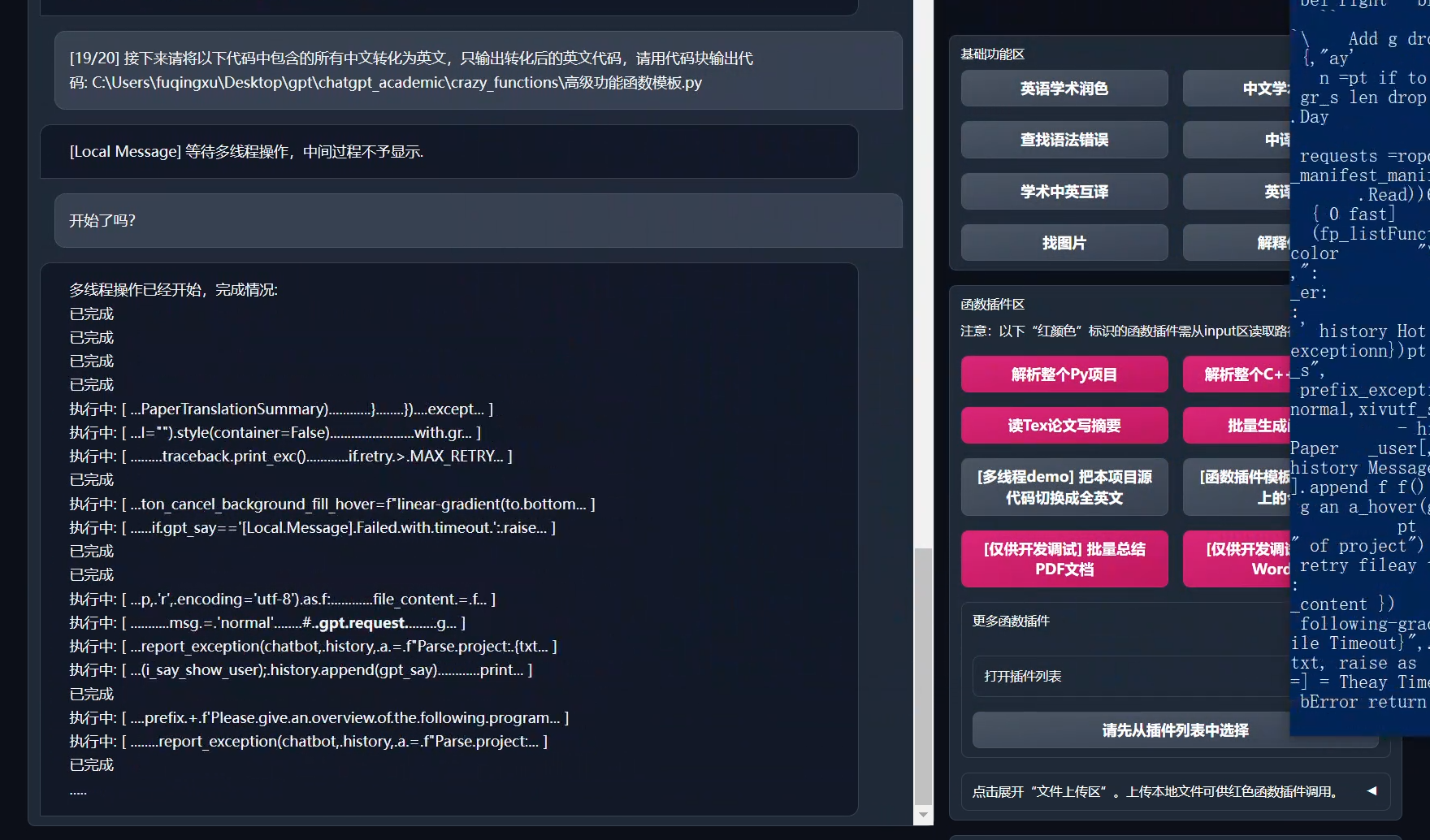
+6. 模块化功能设计
-### 源代码转译英文
+7. 源代码转译英文
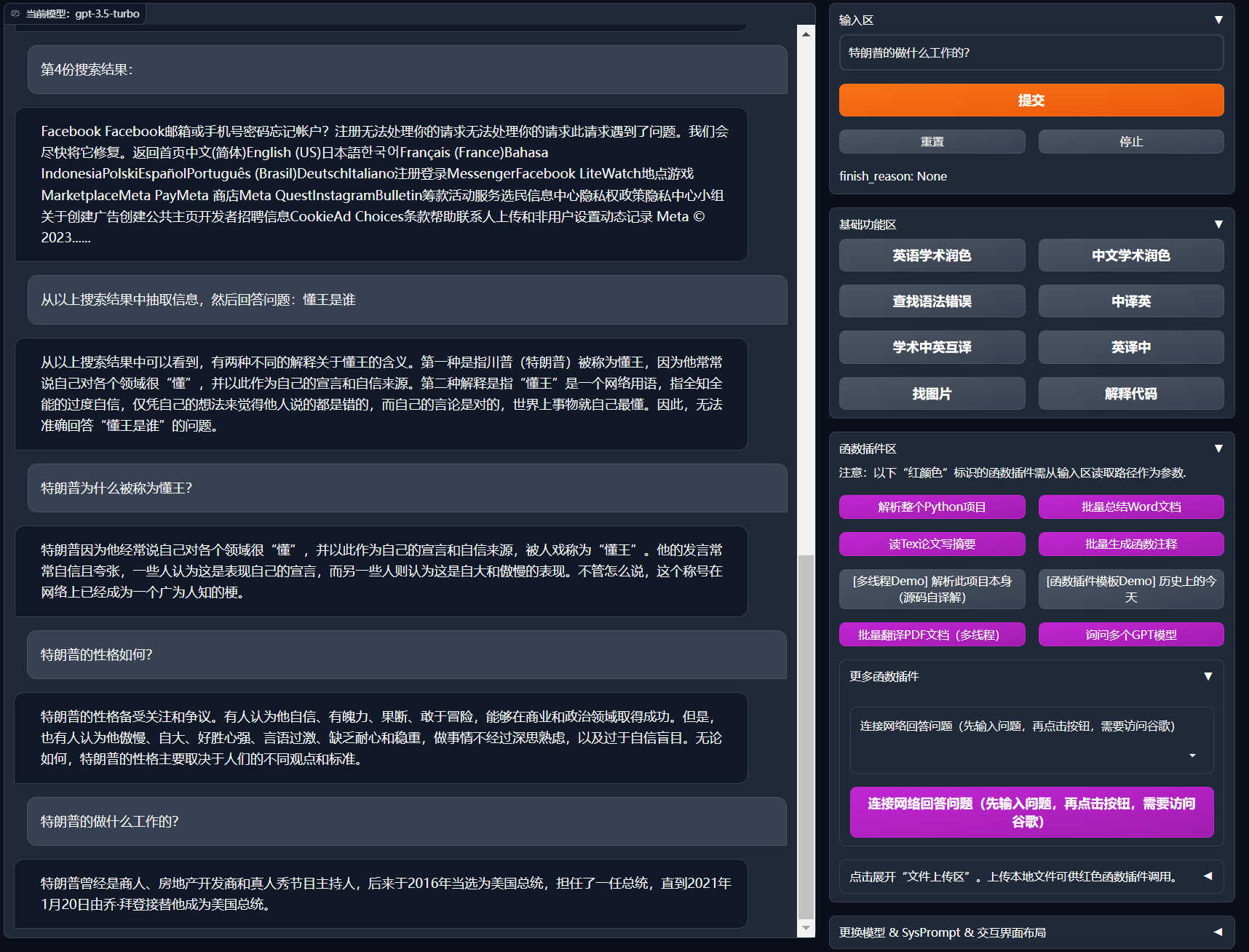
+8. 互联网在线信息综合
+
+
-### Latex论文一键阅读理解与摘要生成
+4. Latex论文一键阅读理解与摘要生成
-### 自动报告生成
+5. 自动报告生成
-### 模块化功能设计
+6. 模块化功能设计
-### 源代码转译英文
+7. 源代码转译英文
+8. 互联网在线信息综合
+
+
+
+